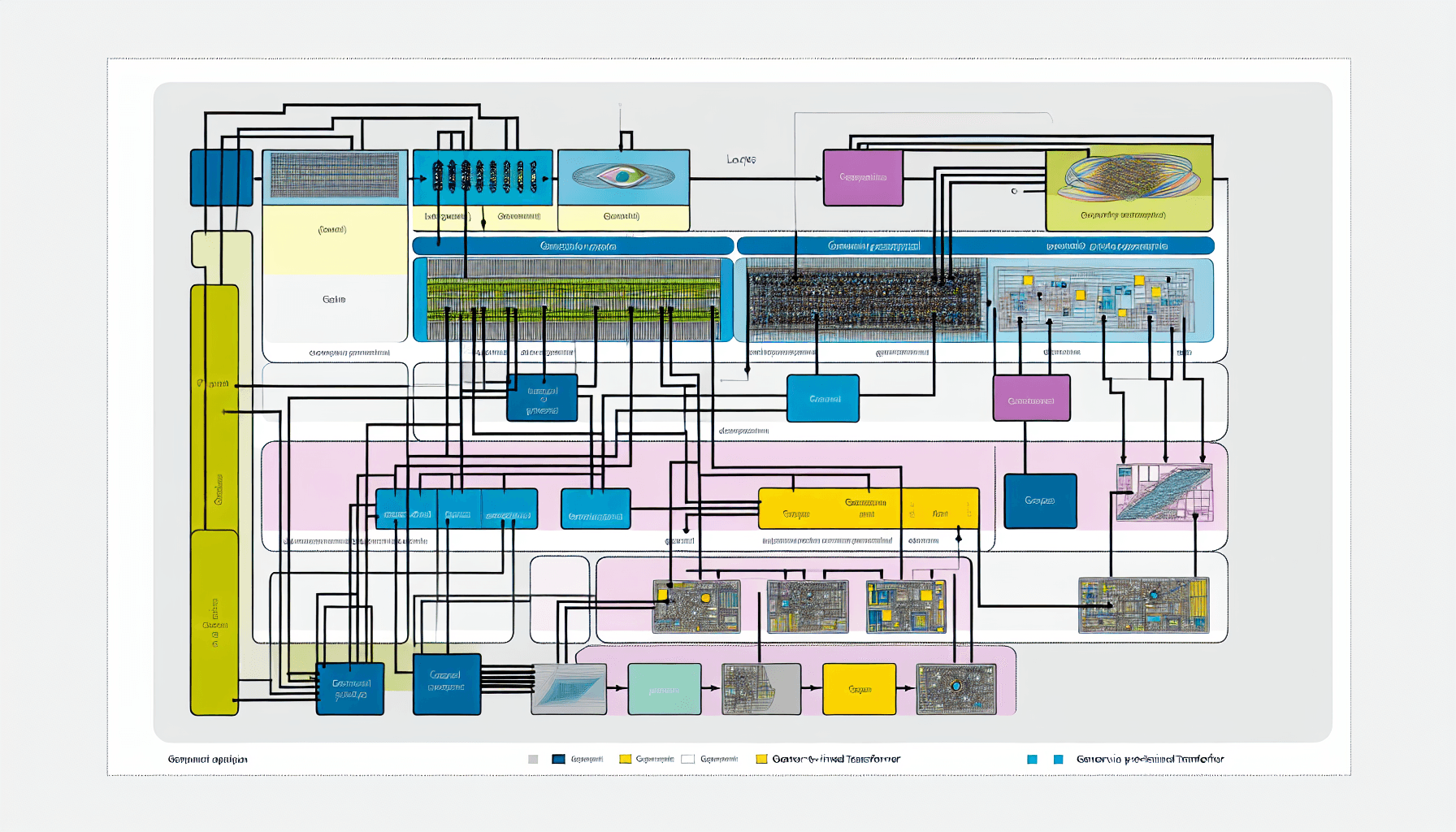
Understanding the Layers of GPT Architecture
Introduction to GPT Architecture
The rapid advancement in artificial intelligence has seen the rise of GPT, short for Generative Pre-trained Transformer. This technology revolutionizes how machines understand and generate human-like text, paving the way for more coherent and contextually relevant AI responses. In this blog, we’ll explore the multi-layered architecture of GPT, shedding light on its operation and its diverse applications.
The Foundation of Generative Pre-trained Transformers
GPT architecture is built on the transformer model, first introduced in the paper ‘Attention is All You Need’ by Vaswani et al. in 2017. The key innovation of the transformer architecture is its reliance on self-attention mechanisms, which allow models to weigh the significance of different words irrespective of their position in the input data. This paradigm shift leads to significant improvements in language modeling and generation tasks.
Pre-training and fine-tuning stages are fundamental to GPT. Initially, the model is pre-trained on a vast corpus of text data in an unsupervised manner. This training helps the model understand language patterns and contexts without specific task-oriented data. Following this, GPT is fine-tuned through supervised learning on smaller, task-specific datasets, allowing it to excel in particular applications.
Understanding The Layers of GPT
At its core, GPT consists of multiple layers of transformers stacked upon each other. Each layer comprises two primary sub-layers: a multi-head self-attention mechanism and a position-wise fully connected feed-forward network. This section will delve into each component and its role in the GPT architecture.
Multi-head Self-Attention Mechanism
The multi-head self-attention mechanism is what allows the transformer to process parts of the input sentence in parallel during training. This parallelization not only speeds up the learning process but also helps the model to capture context from any position in the input sequence. By splitting the attention mechanism into multiple ‘heads’, GPT can focus on different aspects of sentence context, enhancing its ability to understand nuanced meanings.
Position-wise Feed-Forward Networks
Each transformer layer also includes a position-wise feed-forward network, applied individually to each position. These networks consist of fully connected layers which process the outputs from the attention mechanisms, allowing the model to further refine its interpretations and responses.
Layer Normalization and Residual Connections
Beyond the basic components, layer normalization and residual connections are integral to the transformer architecture. Layer normalization is employed after each sub-layer to help stabilize the neural network’s learning process. Residual connections, also known as skip-connections, allow layers to learn incremental feature representations by adding the input of a layer directly to its output, which helps in combating the vanishing gradient problem during deep learning tasks.
GPT Versions and Evolution
Since the inception of the original GPT, multiple versions have been developed, each improving upon the past iterations in both scale and sophistication. This includes GPT-2 and GPT-3, which are notable for their increased parameters, training data, and general capabilities. The evolution of these models showcases significant enhancements in processing language, generating more accurate and contextually appropriate responses.
Applications of GPT in Various Industries
The capabilities of GPT are not confined to mere text generation; its applications span several industries including healthcare, where it assists in drug discovery, and customer service, where it powers conversational bots. The versatile nature of GPT’s architecture makes it a valuable tool for a myriad of tasks ranging from automated translation services to creative content generation.
Challenges and Ethical Considerations
Despite its numerous applications and benefits, GPT’s architecture poses several challenges and ethical considerations. Issues such as data bias, model misuse, and transparency need careful consideration. The development and deployment of GPT models must be accompanied by rigorous ethical standards to ensure fair and responsible use.
Conclusion
Understanding the multiple layers of GPT architecture offers insight into its complex operation and extensive capabilities. As AI continues to evolve, the innovative structure of GPT stands at the forefront of this technological revolution, continuing to enhance how we interact with machine intelligence.
Exploring these architectures not only informs us about the potential and limitations of current AI technologies but also guides future developments in the field, ensuring that AI progresses in a manner that is beneficial and ethical for all.
Thank You for Reading this Blog and See You Soon! 🙏 👋
Let's connect 🚀
Latest Insights
Deep dives into AI, Engineering, and the Future of Tech.

I Tried 5 AI Browsers So You Don’t Have To: Here’s What Actually Works in 2025
I explored 5 AI browsers—Chrome Gemini, Edge Copilot, ChatGPT Atlas, Comet, and Dia—to find out what works. Here are insights, advantages, and safety recommendations.
Read Article


