
Day 3: Reading first books to start building my first AI from scratch
Today, I am excited to share that I have started reading “Build a Large Language Model (from Scratch)” by Sebastian Raschka. Thank you for joining me on this educational journey where we will explore AI, deep learning, and LLM training, from coding in Python, initializing data, and neural networks, to training and fine-tuning datasets for our LLM.
The “coding from scratch” approach provides a comprehensive understanding of complex concepts. It requires me to grasp every detail to explain, build, and validate my technical skills. I highly recommend this method for coding and building applications, and I am now using it to develop my own AI.
The Book
After reading the first few pages, I realized that a background in Python programming is essential. Familiarity with deep learning frameworks like PyTorch or TensorFlow will also enhance your experience.
Don’t worry, I have added and will keep updating blogs about development with Python, AI fundamentals, Machine Learning, Deep Learning, PyTorch, TensorFlow, and more about Artificial Intelligence.
You can find all these resources in my blog : Data Ccientist and AI with Python, Python for AI, Machine Learning, Deep Learning, PyTorch, TensorFlow, and more.
Understanding large language models – LLM
Large Language Models (LLMs) are a type of artificial intelligence (AI) designed to understand, generate, and interact with human language. They are built using deep learning techniques, particularly neural networks (Deep Learning), and are trained on vast amounts of text data.

Large Language Models (LLMs), such as OpenAI’s ChatGPT, are advanced neural network models developed over the past few years. They have revolutionized the field of natural language processing (NLP), ushering in a new era for how machines understand and generate human language.
From Traditional NLP to LLMs
Before LLMs, traditional NLP methods excelled at simple tasks like spam email classification and basic pattern recognition, relying on handcrafted rules or simpler models. However, these methods struggled with complex language tasks that required deep understanding and text generation, such as analyzing detailed instructions or writing coherent text.
Unlike earlier NLP models designed for specific tasks, contemporary LLMs demonstrate a broad proficiency across a wide range of NLP tasks. This versatility marks a significant improvement over older models that performed well only in narrow applications.
For example, older models couldn’t write an email from a list of keywords, a task easily handled by modern LLMs.
Understanding the Capabilities of LLMs
LLMs have remarkable abilities to understand, generate, and interpret human language. It’s important to note that when we say these models “understand” language, we mean they can process and produce text that is coherent and contextually relevant, not that they have human-like consciousness.
The Role of Deep Learning
The progress in LLMs is driven by deep learning, a branch of artificial intelligence (AI) that focuses on neural networks. LLMs are trained on massive amounts of text data, allowing them to process contextual information and the nuances of human language that earlier approaches couldn’t capture. This enables them to excel in various NLP tasks, including text translation, sentiment analysis, speech recognition and more.
I will talk about other AI algorithms in the future, subscribe to receive updates.
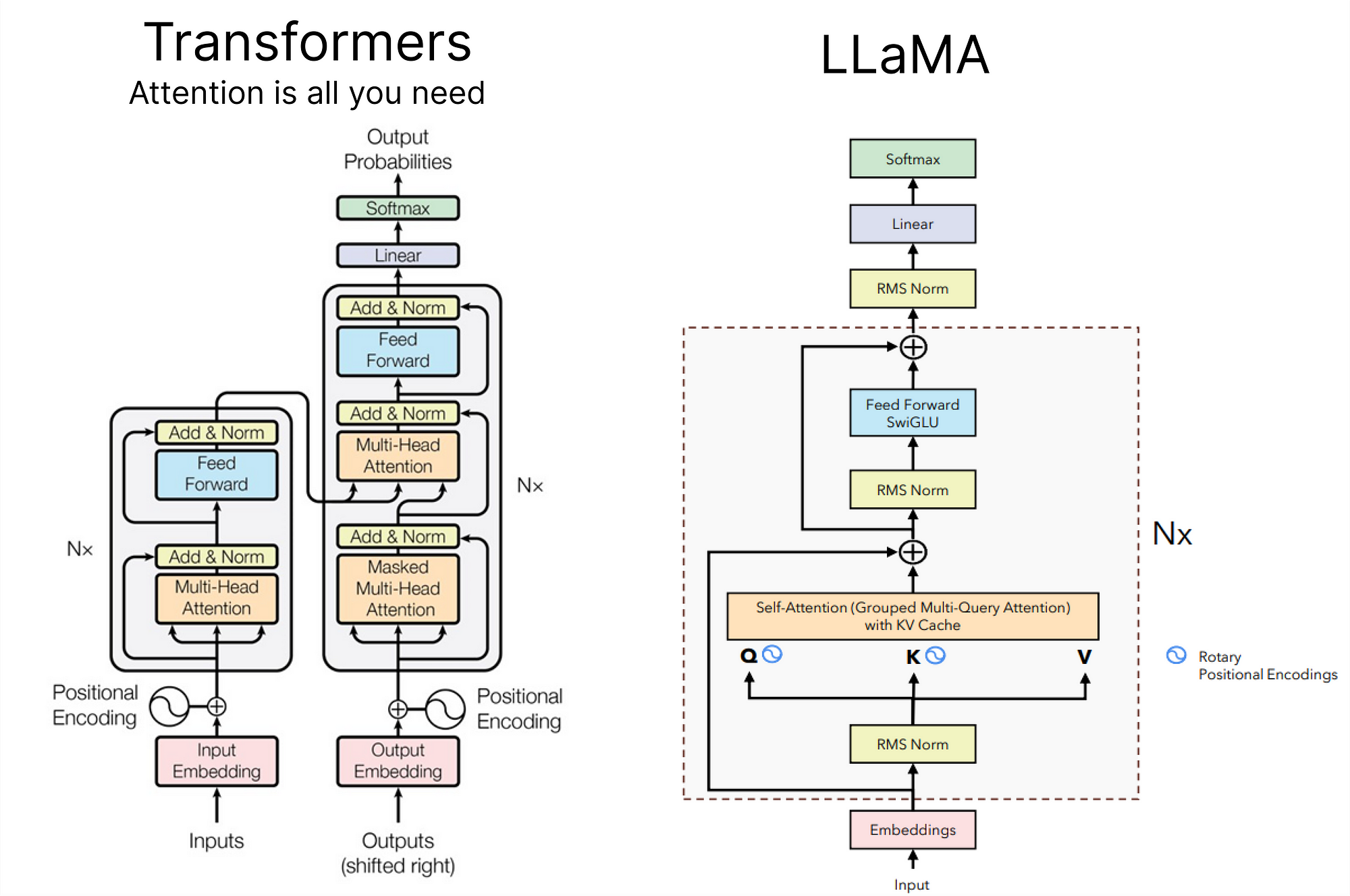
The Transformative Power of the Transformer Architecture
The success of LLMs is largely due to the transformer architecture and extensive training on large datasets. This combination allows LLMs to capture linguistic nuances and contextual patterns that are challenging to encode manually. The use of transformer-based models has fundamentally transformed NLP, providing more powerful tools for understanding and interacting with human language.
The first significant papers on large language models (LLMs) using transformers were published by researchers at Google and OpenAI. The most notable and foundational papers include:
- Attention Is All You Need (2017) by Vaswani et al.
- This paper introduced the transformer model, which became the foundation for all subsequent large language models. It demonstrated that a model based solely on attention mechanisms could achieve superior performance compared to recurrent and convolutional neural networks for various tasks in natural language processing (NLP).
- Link to paper
- Improving Language Understanding by Generative Pre-Training (GPT) (2018) by Radford et al.
- This paper presented the first Generative Pre-trained Transformer (GPT) model. It showed that unsupervised pre-training followed by supervised fine-tuning significantly improved performance on a wide range of NLP tasks.
- Link to paper
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018) by Devlin et al.
- BERT (Bidirectional Encoder Representations from Transformers) introduced a bidirectional approach to language modeling, significantly improving the state-of-the-art for a variety of NLP tasks through fine-tuning.
- Link to paper
- Language Models are Few-Shot Learners (GPT-3) (2020) by Brown et al.
- This paper described GPT-3, an LLM with 175 billion parameters, and demonstrated its remarkable ability to perform a variety of tasks with little to no fine-tuning (few-shot learning).
- Link to paper
These papers laid the groundwork for the development and widespread adoption of transformer-based large language models in NLP.
Learning to Implement LLMs
In the next blogs, I will break down the complex concepts behind these models and guide you step-by-step through the process of building your own LLM or GPT Like model using the transformer architecture. Whether you’re a seasoned developer or just starting out, our tutorials will be designed to help you understand and implement these powerful models.
What to Expect in Our Upcoming blogs
- Introduction to Transformers
- We’ll start with the basics, explaining what transformers are and why they have revolutionized NLP. You’ll learn about the core components like attention mechanisms and how they work together to process and generate language.
- Setting Up Your Environment
- Before diving into code, we’ll help you set up your development environment. This includes installing necessary libraries, understanding the tools you’ll need, and ensuring everything is ready for smooth implementation.
- Data Preparation
- Data is the fuel for any machine learning model. We’ll show you how to collect, clean, and prepare your data to train your ChatGPT-like model. This step is crucial for achieving good performance and results.
- Building the Model
- Now comes the exciting part! We’ll guide you through writing the code to build your transformer-based model. This will include defining the architecture, setting up the training process, and understanding the hyperparameters involved.
- Training and Fine-Tuning
- Training a model can be a complex task, but we’ll make it manageable by breaking it down into easy-to-follow steps. You’ll learn how to train your model, monitor its performance, and fine-tune it to improve accuracy and efficiency.
- Testing and Deployment
- Finally, we’ll show you how to test your model to ensure it works as expected. We’ll also cover deployment, so you can integrate your ChatGPT-like model into applications and see it in action.
Why Follow This Series ?
- Hands-On Learning: Each post will include practical examples and code snippets that you can follow along with.
- Comprehensive Guides: From theory to implementation, we’ll cover everything you need to know.
- Community Support: Join our community of learners and experts to share your progress, ask questions, and get feedback.
Stay tuned for our next blog post, where we’ll kick things off with an introduction to transformers. We can’t wait to embark on this learning journey with you!
Conclusion
Day 3 marks a significant step in our journey to build an AI from scratch. Starting with “Build a Large Language Model (from Scratch)” by Sebastian Raschka, we’ve laid a strong foundation in Python, deep learning frameworks, and LLM training. This approach offers a deep understanding of the complexities involved in LLMs, which have revolutionized natural language processing.
Our exploration has shown how the transformer architecture and deep learning have advanced NLP, enabling nuanced language understanding and broad task proficiency. Moving forward, we’ll provide step-by-step guidance on implementing a ChatGPT-like model. Stay tuned for more updates and tutorials on Python for AI, machine learning, and deep learning. Thank you for joining me on this journey to unlock the potential of AI and LLMs.
Thank You for Reading this Blog and See You Soon! 🙏 👋
Let's connect 🚀
Latest Insights
Deep dives into AI, Engineering, and the Future of Tech.

I Tried 5 AI Browsers So You Don’t Have To: Here’s What Actually Works in 2025
I explored 5 AI browsers—Chrome Gemini, Edge Copilot, ChatGPT Atlas, Comet, and Dia—to find out what works. Here are insights, advantages, and safety recommendations.
Read Article


