
Creating a Large Language Model from Scratch: A Step-by-Step Guide
Building a Large Language Model (LLM) from scratch is a complex yet fascinating process that involves several stages, from data collection to model evaluation. In this blog post, we will guide you through the steps required to create your own LLM, covering the essential aspects of data preprocessing, model architecture, training, and more.
1. Overview
What is a Large Language Model?
Large Language Models (LLMs) are advanced AI models designed to understand and generate human-like text based on the input they receive. These models are trained on vast amounts of text data and can perform a variety of language-related tasks such as translation, summarization, and question-answering.
2. Data Collection
The first step in creating an LLM is gathering a large and diverse dataset. This dataset should include a wide range of text from different domains to ensure the model can generalize well.
- Sources: Books, articles, websites, social media, etc.
- Quality: Ensure the data is clean and relevant.
- Quantity: The more data, the better the model’s performance.
3. Data Preprocessing
Once the data is collected, it needs to be cleaned and preprocessed to make it suitable for training.
- Tokenization: Breaking down text into tokens (words, subwords, or characters).
- Normalization: Converting text to a standard format (e.g., lowercasing, removing punctuation).
- Filtering: Removing irrelevant or low-quality data.
4. Model Architecture
Choosing the right architecture is crucial for the performance of your LLM.
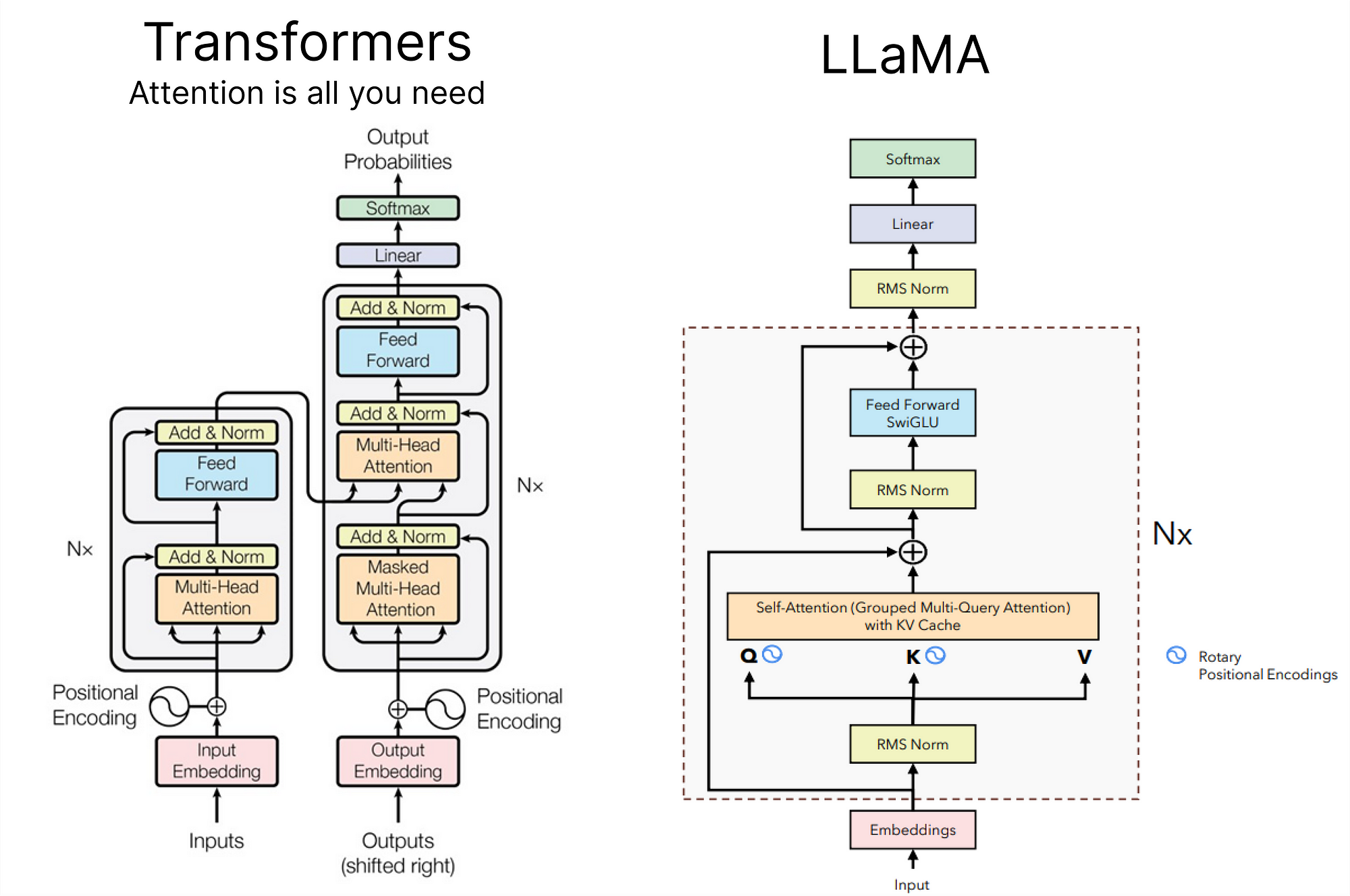
- Transformer Architecture: The transformer model, introduced in the paper “Attention is All You Need,” is the backbone of most state-of-the-art LLMs.
- Parameters: Decide on the number of layers, heads, and hidden units.
- Variants: Consider architectures like GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), or custom variations.
5. Training the Model
Training an LLM requires substantial computational resources and time.
- Hardware: GPUs or TPUs are essential for efficient training.
- Training Data: Ensure the dataset is shuffled and split into training and validation sets.
- Optimization: Use optimization algorithms like Adam and learning rate schedules.
- Batch Size: Adjust batch size according to the available memory.
6. Fine-Tuning
After the initial training, fine-tuning the model on specific tasks or domains can significantly improve its performance.
- Task-Specific Data: Use a smaller, domain-specific dataset.
- Transfer Learning: Leverage the pre-trained model’s knowledge and adapt it to new tasks.
7. Evaluation
Evaluating the LLM is crucial to understand its strengths and weaknesses.
- Metrics: Use metrics like perplexity, BLEU score, or human evaluation.
- Benchmarking: Compare the model’s performance against existing models on standard benchmarks.
8. Deployment
Finally, deploying the LLM involves making it accessible for real-world applications.
- API: Create an API for easy integration with other systems.
- Scalability: Ensure the deployment can handle varying loads efficiently.
- Monitoring: Continuously monitor the model’s performance and update it as needed.
Conclusion
Creating a Large Language Model from scratch is a challenging but rewarding endeavor. By following these steps, you can develop a powerful LLM capable of performing a wide range of language tasks. Remember, the key to success lies in the quality of your data, the robustness of your model architecture, and the efficiency of your training process.
Thank You for Reading this Blog and See You Soon! 🙏 👋
Let's connect 🚀
Latest Insights
Deep dives into AI, Engineering, and the Future of Tech.

I Tried 5 AI Browsers So You Don’t Have To: Here’s What Actually Works in 2025
I explored 5 AI browsers—Chrome Gemini, Edge Copilot, ChatGPT Atlas, Comet, and Dia—to find out what works. Here are insights, advantages, and safety recommendations.
Read Article


